美国东海岸数据中心的数据库服务器含有无法复制到西海岸数据中心
我们GitHub的所有人都为这次事件给您们每个人带来的影响深表歉意。我们深智您们对GitHub寄予的信任,并为构建的弹性系统让我们平台能够保持高可用性而引以为豪。但在这次事件中,我们让您们失望了,对此深感抱歉。虽然我们消除不了GitHub平台长时间无法使用所带来的问题,但我们可以解释导致此事件发生的事件、吸取的教训以及我们公司采取的步骤,以便更好地确保不再发生这种情况。
GitHub经历了一次故障事件导致服务质量下降了24小时又11分钟。虽然我们平台的某些部分不受此事件影响,但多个内部系统还是受到了影响,导致我们显示过时且不一致的信息。最终,用户数据没有丢失;然而,数据库写入操作还是出现了几秒钟的手动协调。就事件过程中的大多数时间而言,GitHub也无法处理Web钩子(webhook)事件,也无法构建和发布GitHub Pages网站。
背景情况
面向用户的GitHub服务大多数在我们自己的数据中心设施中运行。数据中心拓扑结构旨在提供一个强大且可扩展的边缘网络,该网络在几个区域数据中心的前端运行,为处理我们的计算和存储工作负载提供支持。尽管该设计中的物理和逻辑部件已内置了多层冗余机制,但站点仍然有可能有一段时间无法彼此联系。
10月21日22:52UTC,由于100G光设备出故障,更换该设备的日常维护工作导致我们的美国东海岸网络中心与我们主要的美国东海岸数据中心之间的连接断开。这两个地方之间的连接在43秒后恢复正常,但正是这次短暂的故障引发了一系列事件,导致服务质量下降了24小时又11分钟。
GitHub网络架构的大体描述,包括两个物理数据中心、3个接入点(POP,又译入网点)以及通过对等互联(peering)的多个区域中的云容量。
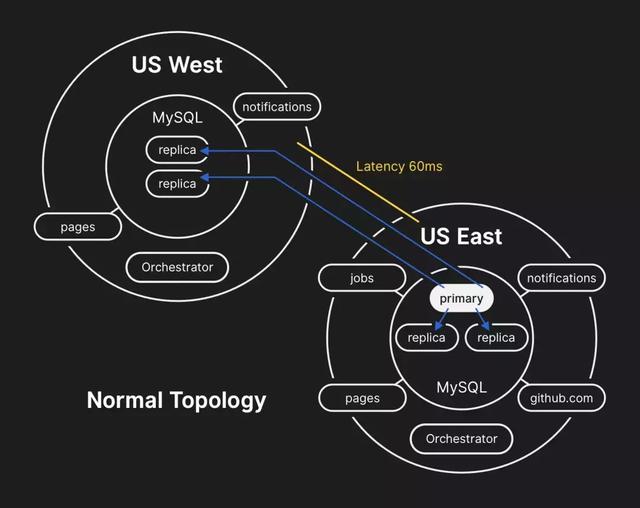
在过去,我们已讨论了我们如何使用MySQL来存储GitHub元数据以及为确保MySQL高可用性采用的方法。GitHub运行多个MySQL集群,集群大小从几百GB到约5TB不等,每个集群最多有几十个读取副本来存储非Git元数据,因此我们的应用程序可以提供合并请求(pull request)和问题单(issue)、管理身份验证、协调后台处理,并且提供原始Git对象存储之外的其他功能。应用程序不同部分的不同数据通过功能分区(sharding)存储在各个集群上。
为了大规模提高性能,我们的应用程序将写入引到每个集群的相关主系统,但在绝大多数情况下,将读取请求委派给一小部分的副本服务器。我们使用Orchestrator来管理我们的MySQL集群拓扑结构,并处理自动故障切换。Orchestrator在此过程中考虑了诸多变化因素,并建立在Raft之上以确保共识。Orchestrator可以实现应用程序无法支持的拓扑结构,因此必须小心谨慎,让Orchestrator的配置与应用程序级别的期望保持一致。
事件时间线
10月21日22:52 UTC:
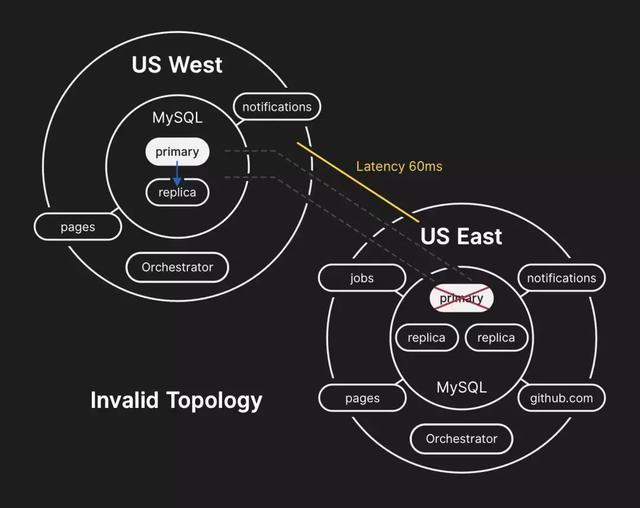
美国东海岸数据中心的数据库服务器含有无法复制到西海岸数据中心的短暂写入内容。由于两个数据中心中的数据库集群现在含有另一个数据中心中没有的写入内容,我们在故障后无法将主数据库安全地切换到东海岸数据中心。
10月21日22:54 UTC
内部监控系统开始发出警报,表明系统遇到众多故障。工程师查明,众多数据库集群的拓扑结构处于意外的状态。查询Orchestrator API后显示,数据库复制拓扑结构只包括来自西海岸数据中心的服务器。
10月21日23:07 UTC
响应团队决定手动锁住内部部署工具,以防出现任何另外的变化。响应团队将网站置于黄色警报状态。情形自动升级为活跃事件,并向事件协调员发出警报。事件协调员加入进来,2分钟后决定换成红色警报状态。
10月21日23:13 UTC
这时我们知道这个问题影响了多个数据库集群。GitHub数据库工程团队的工程师开始调查现状,以便搞清楚需要采取什么措施,才能手动配置东海岸的数据库作为每个集群的主数据库,并重新构建复制拓扑结构。东海岸集群中的几秒写入数据没有复制到西海岸,因而新写入数据无法复制回到东海岸。
对于绝大多数数据库调用而言,在东海岸运行、依赖将信息写入到西海岸MySQL集群的应用程序目前无法处理横越全国的往回带来的额外延迟。因此导致许多用户无法使用我们的服务。但为了确保用户数据的一致性,我们认为延长服务降级的时间是必要的。
10月21日23:19 UTC
查询数据库集群的状态后,我们显然需要停止运行中的任务,这些任务在写入关于推送等操作的元数据。我们明确决定,暂停Web钩子传送和GitHub Pages构建,局部降低网站可用性,而不是危及我们已经从用户处收到的数据。换句话说,数据完整性比网站可用性和恢复时间来得更重要。
10月22日00:05 UTC
事件响应团队的工程师开始制定计划以解决数据不一致性,并为MySQL落实故障切换程序。我们更新了状态,告知用户我们将对内部数据存储系统执行有节制的故障切换。
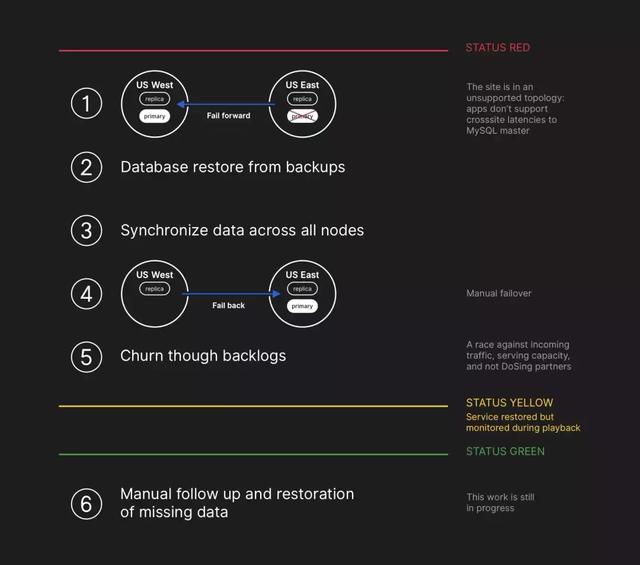
虽然MySQL数据每隔4小时备份一次、保留多年,但备份内容存储在异地的公共云存储服务中。恢复数TB备份数据花了几小时,时间主要花在了传输来自远程备份服务的数据上。解压缩、校验和、准备以及将庞大备份文件装入到刚配置好的MySQL服务器上用去了大部分的时间。
10月22日00:41 UTC
开始对所有受影响的MySQL集群进行备份。同时,多个工程师团队设法缩短传输和恢复时间,又不进一步降低网站可用性或导致数据损坏。
10月22日06:51 UTC
在东海岸数据中心,几个集群完成了靠备份恢复的工作,开始复制来自西海岸的新数据。这导致对于在跨越全国的链路上执行写入操作的页面而言,网站加载时间缓慢,但如果读取请求出现在刚恢复的副本上,从那些数据库集群读取数据的页面会返回最新结果。其他较庞大的数据库集群仍在恢复中。
10月22日11:12 UTC
所有主数据库在东海岸再次建立。由于写入内容现在被引到与我们的应用层在同一物理数据中心的数据库服务器,这导致网站响应极其缓慢。仍有众多数据库读取副本比主数据库延迟几小时,因而导致用户看到不一致的数据。我们将读取负载分摊到庞大的读取副本池上,针对我们服务的每个请求就很有可能“命中”延迟几小时的读取副本。
10月22日13:15 UTC
这时GitHub.com上的流量负载接近峰值。复制延迟在增加,而不是逐步降低。我们开始在东海岸公共云配置更多的MySQL读取副本。
10月22日16:24 UTC
副本同步后,我们切换到原始拓扑结构,以解决延迟/可用性问题。我们开始处理积压的数据时,让服务继续处于红色警报状态。
10月22日16:45 UTC
我们不得不均衡分摊数据积压带来的更大负载,让服务尽快回到100%的可用性。排入队列的有500多万个钩子事件和8000多个Pages构建。
我们在重新处理这些数据时,处理了约200000个因超出内部TTL而丢弃的Web钩子载荷。一发现这个问题,我们暂停了处理工作,暂时调高了该TTL。
为了避免进一步影响状态更新的可靠性,我们仍处于性能降级状态,直到处理完全部积压的数据,并确保服务明显回到正常的性能级别。
10月22日23:03 UTC
所有待处理的Web钩子和Pages构建已处理完毕,所有系统的完整性和正常操作运行已得到了核实。网站状态更新到绿色,以示正常
 戴尔服务器销售中心
戴尔服务器销售中心


